Méta affirme que son nouveau modèle d’IA open source, ImageBind, est une étape vers des systèmes qui imitent mieux la façon dont les humains apprennent, établissant des liens entre plusieurs types de données à la fois de la même manière que les humains s’appuient sur plusieurs sens. L’intérêt général pour l’IA générative a explosé ces dernières années avec la montée en puissance des générateurs de texte en image comme DALL-E d’OpenAI et des modèles conversationnels comme ChatGPT. Ces systèmes sont formés à l’aide d’ensembles de données massifs d’un certain type de matériel, comme des images ou du texte, afin qu’ils puissent finalement apprendre à produire les leurs.
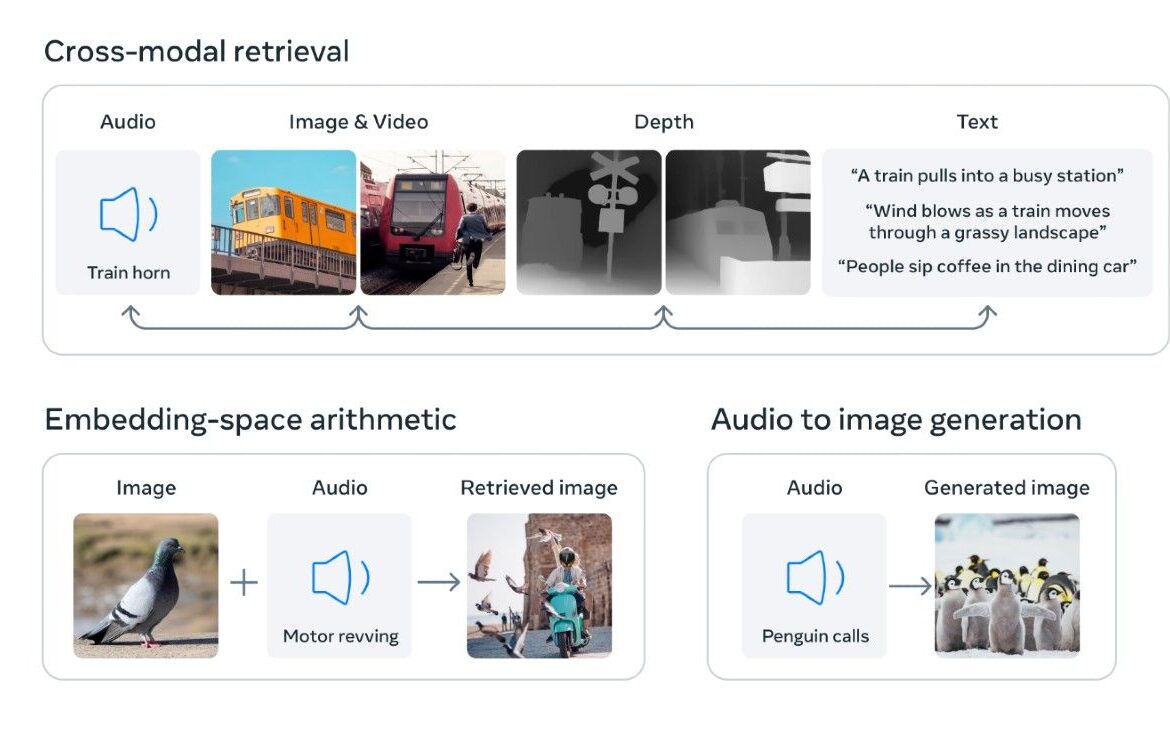
Avec ImageBind, Meta vise à faciliter le développement de modèles d’IA capables d’appréhender la situation dans son ensemble. Prendre un plus « holistique” approche de l’apprentissage automatique, il peut relier six types de données différents : texte, visuel (image/vidéo), audio, profondeur, température et mouvement. La possibilité d’établir des liens entre plusieurs types de données permet au modèle d’IA d’assumer des tâches plus complexes et de produire des résultats plus complexes. ImageBind pourrait être utilisé pour générer des visuels basés sur des clips audio et vice versa, selon Meta, ou ajouter des éléments environnementaux pour une expérience plus immersive.

Selon Méta, «ImageBind équipe les machines d’une compréhension holistique qui relie les objets d’une photo à leur son, à leur forme 3D, à leur chaleur ou à leur froid et à leur mouvement.« Les modèles d’IA actuels ont une portée plus limitée. Ils peuvent apprendre, par exemple, à repérer des modèles dans des ensembles de données d’images pour générer à leur tour des images originales à partir d’invites de texte, mais ce que Meta envisage va beaucoup plus loin.
Les images statiques pourraient être transformées en scènes animées à l’aide d’invites audio, dit Meta, ou le modèle pourrait être utilisé comme « une manière riche d’explorer les souvenirs » en permettant à une personne de rechercher ses messages et ses bibliothèques multimédias pour des événements ou des conversations spécifiques à l’aide d’invites textuelles, audio et image. Cela pourrait amener quelque chose comme la réalité mixte à un nouveau niveau. Les futures versions pourraient apporter encore plus de types de données pour pousser ses capacités plus loin, comme « le toucher, la parole, l’odorat et les signaux IRMf du cerveau » pour « permettre des modèles d’IA centrés sur l’humain plus riches.”
ImageBind n’en est encore qu’à ses balbutiements, et le Méta les chercheurs invitent les autres à explorer le modèle d’IA open-source et à s’en inspirer. L’équipe a publié un article parallèlement au billet de blog détaillant la recherche, et le code est disponible sur GitHub.
Source : Méta, GitHub